
Public Domain Project
Public Domain Intellectual Properties built with Story Protocol
Overview
The public domain project introduces public domain intellectual properties to Story Protocol to showcase the concepts in the protocol. The project retrieves data from public domain literature for Story Protocol and provides an explorer for users to view and operate with this data. The project serves three main purposes:
- Provide a dashboard to interact with entities on Story Protocol.
- Help users learn how Story Protocol works.
- Provide data on Story Protocol for users to experiment and build on top of.
What is the Public Domain?
Here is the definition of Public Domain on Wikipedia:
The public domain (PD) consists of all the creative work to which no exclusive intellectual property rights apply. These rights may have expired, been forfeited, expressly waived, or may be inapplicable. Because no one holds the exclusive rights, anyone can legally use or reference those works without permission.
What Public Domain IPs are Collected
For the Story Protocol Alpha release, the Public Domain Project focuses on collecting public domain literary works, focusing on the fiction genre. The workflow includes fetching the data from public websites and storing them in a database. The metadata and contents of the literary works are also organized for optimal access.
These literary works are collected from the following data sources:
The project also collects data from other public available websites that share public domain contents.
Exploring Public Domain IP in Story Protocol
You can visit Story Protocol Explorer to explore the public domain IPs in Story Protocol. You can view all the Transactions, IP Orgs or Assets by clicking the menu item from the left side of the page. If you go to the IP Orgs page and click one of the IP Org, you will browse into the IP Org page like the following snapshot.
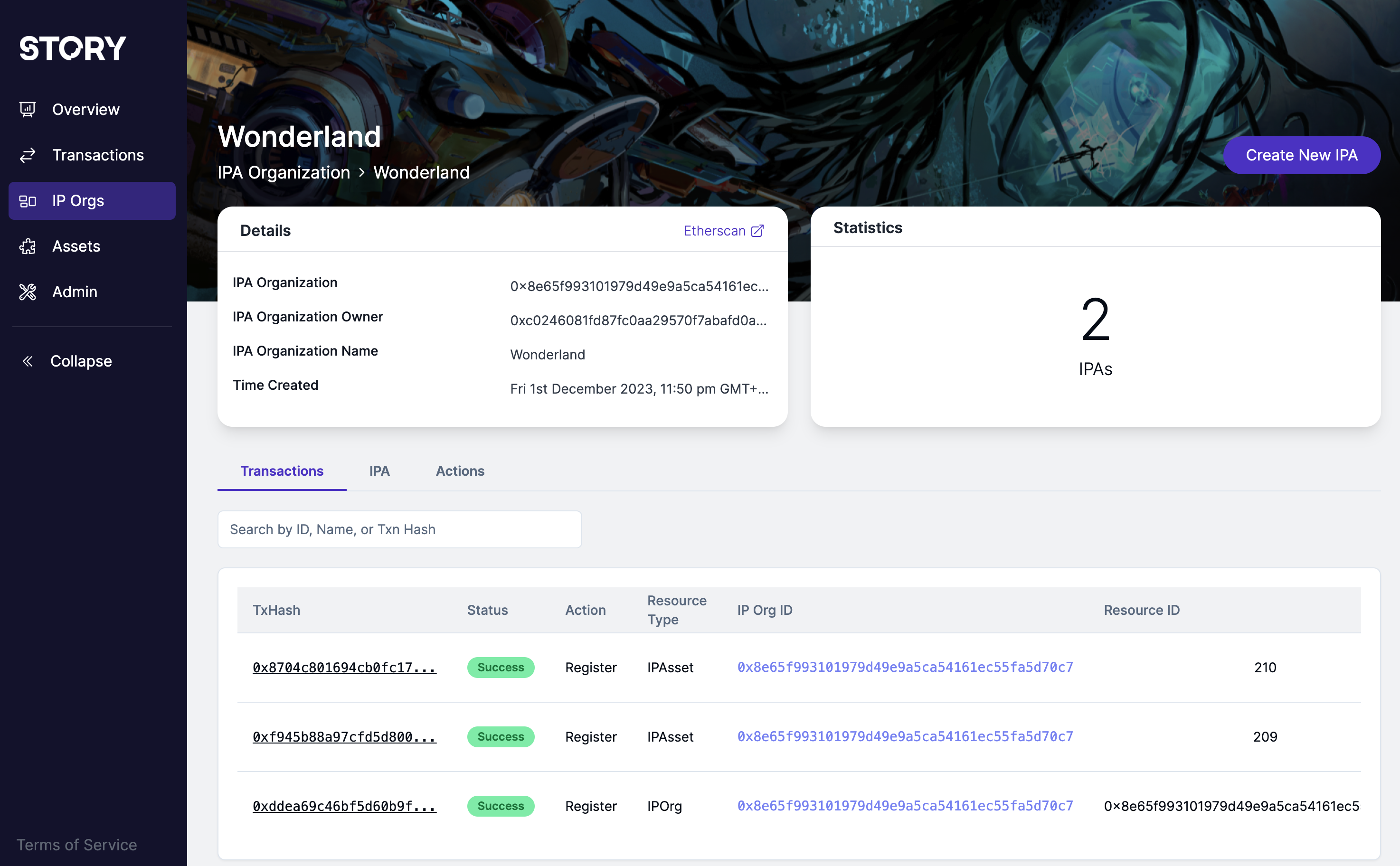
Snapshot 1: The IP Org Page Detail Information Page
From Snapshot 1, you can see there are two IP assets created under this IP org, and there are three transactions on the bottom. For each transaction, you can click the TxHash on the left column to view the Story Protocol transaction, the Transaction Detail page shows the TxHash link to the Sepolia explorer for the transaction:
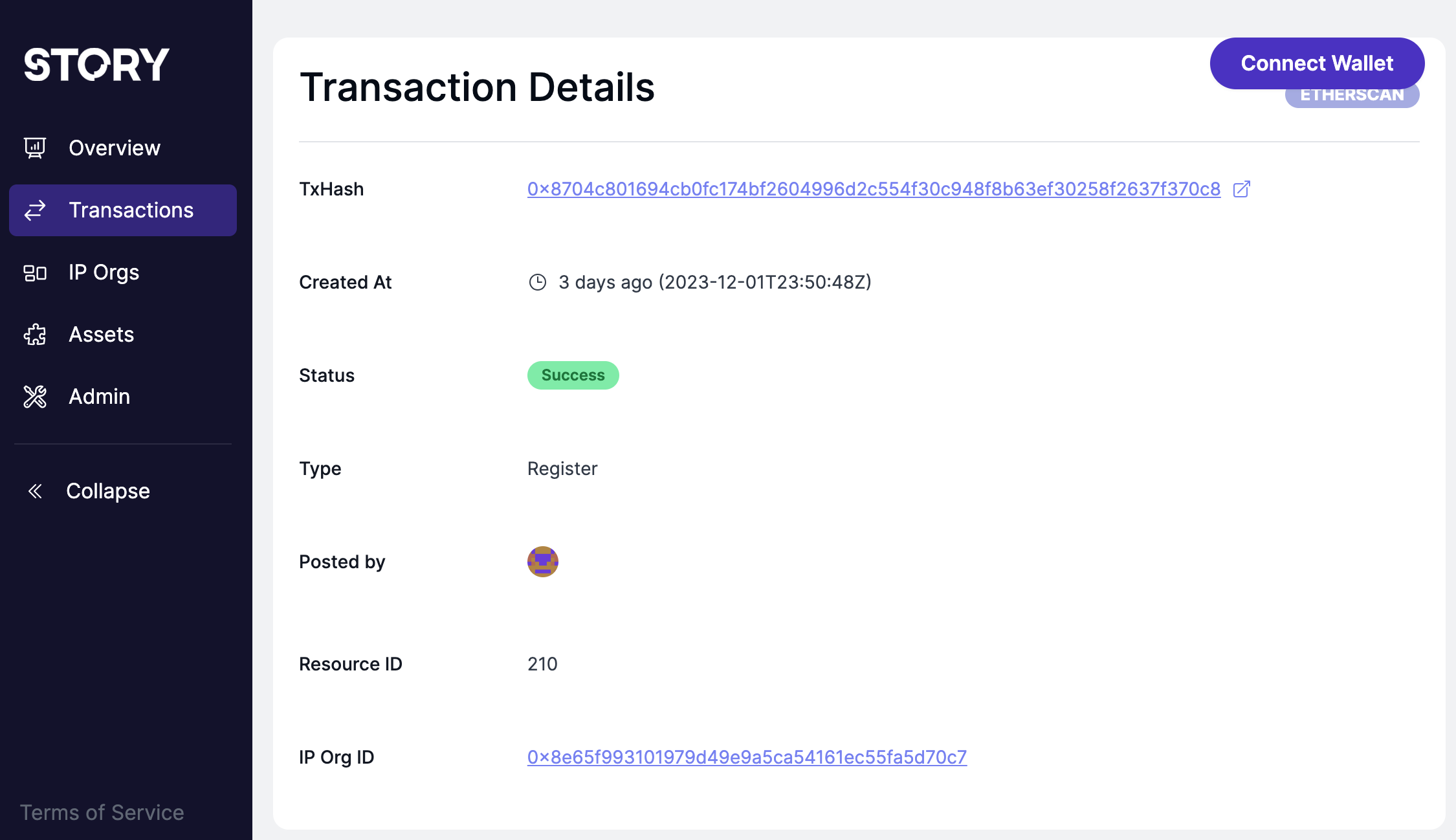
Snapshot 2: The Transaction Detail Page
In the IPA tab in Snapshot 1, you can view all the IP assets belong to this IP Org, or you can click the Assets menu item on the left side to view all the IP Assets in the Story Protocol.
Note
The Story Protocol Explorer is not specific for Public Domain data only. You can also view the data you created with Story Protocol.
Technical Overview
This section gives you a high level overview of the architecture of Public Domain Project. It leverages a data pipeline approach to retrieve and generate the data from public domain IPs for Story Protocol. The architecture of the pipeline is shown on the following diagram:
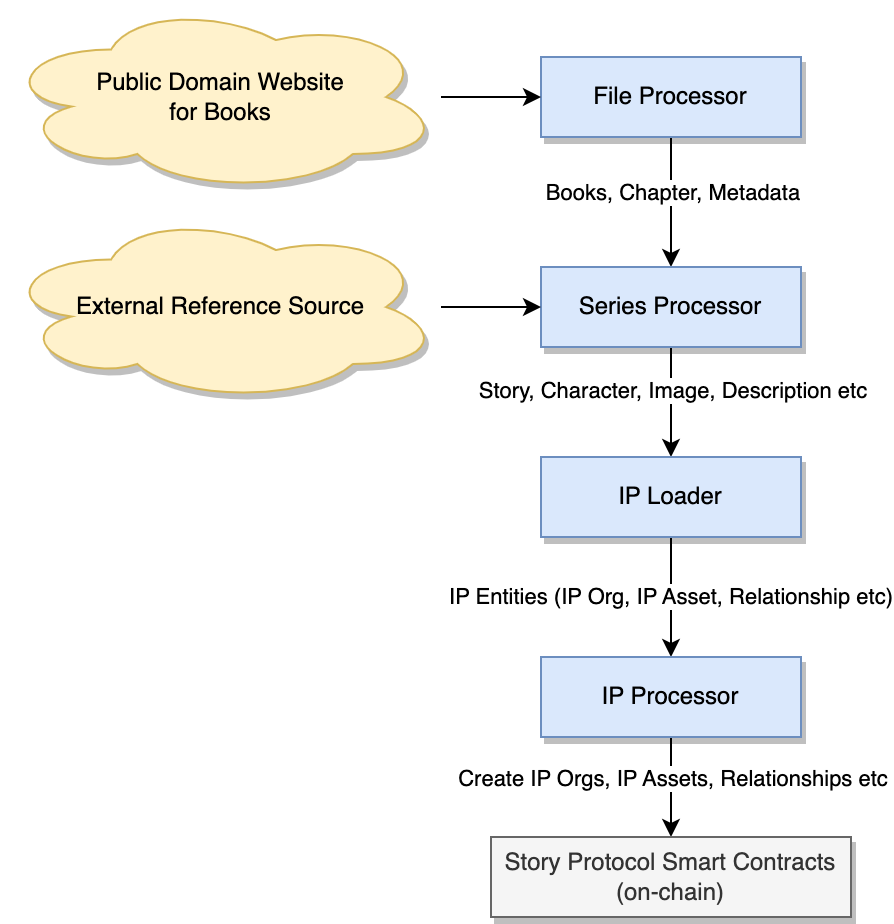
The architecture consists of the following components.
File Processor
The file processor is for downloading the online contents of each of book from a specific URL and storing the contents in a backend database. Meanwhile, it also retrieves the metadata for the book via the RDF (Resource Description Framework) URL. While processing the content, it also processes the chapters, tags and authors of each book.
Series Processor
The series processor is used for generating the data types under the management of Story Protocol. It uses ChatGPT and generative AI to generate assets matching the data models in Story Protocol. For example, the processor can split the book into several stories, detect characters from the stories, and detect relationships between stories and characters. The processor also generates the description and images for each character with generative AI.
IP Loader
Before interacting with Story Protocol to create IP related data (IP Orgs, IP Asset, Relationship etc), the pipeline requires the IP Loader to generate the parameters to call Story Protocol SDK to perform the actions to create and config these entities. Once the parameters are generated, the pipeline will need store the parameters for the next step.
IP Processor
The IP processor reads the parameters generated from the last step and creates transactions by calling Story Protocol SDK to create IP entities (IP Orgs, IP Asset and Relationships) for Public Domain.
Summary
We have gone through the introduction of Public Domain Project. Please refer to Public Domain IP Repository for the code. We recommend that you continue reading the next section to start learning how to build applications with Story Protocol.
Updated 5 months ago